
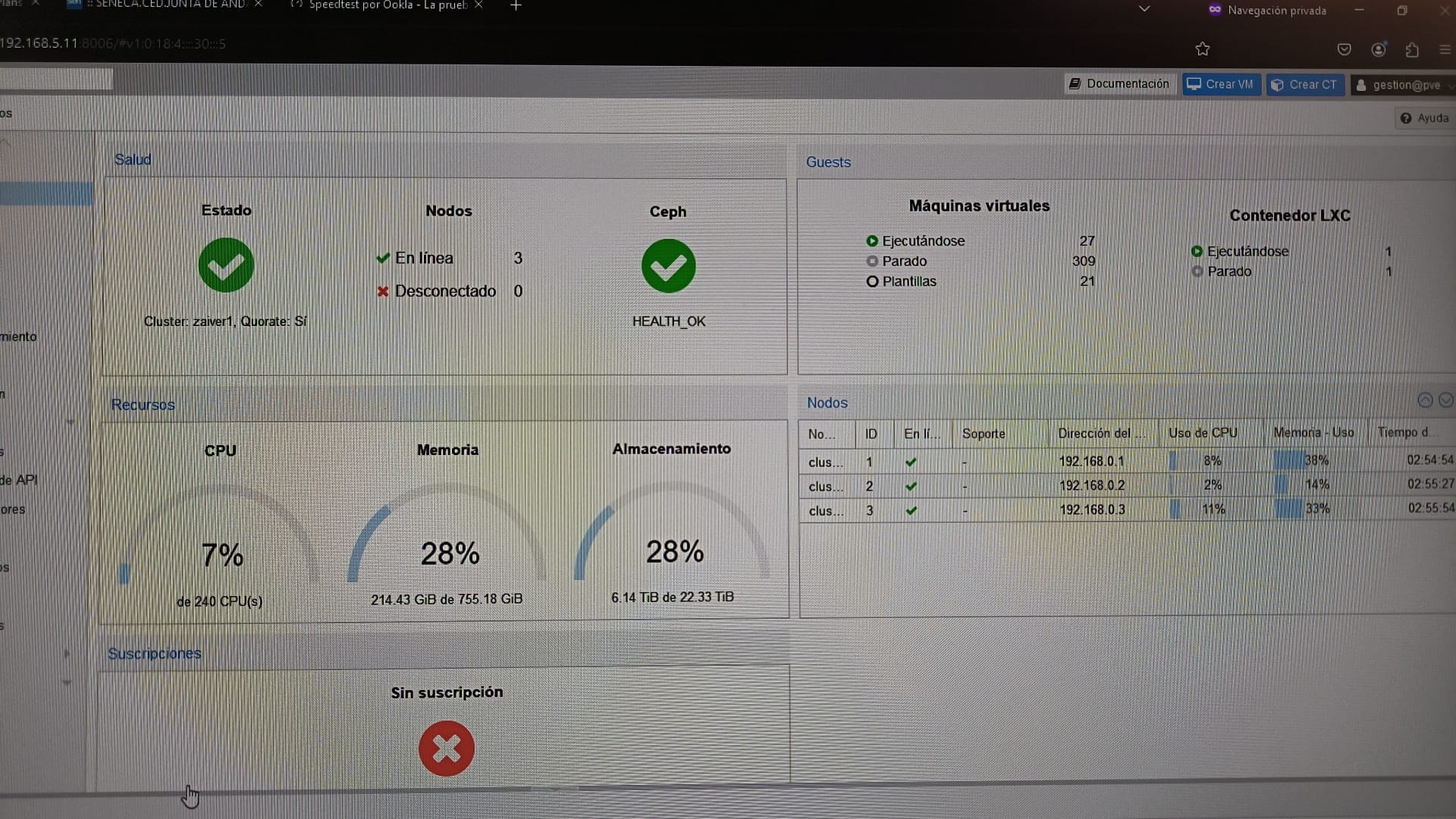
Este verano de 2024, dimos un paso clave en la modernización de nuestra infraestructura IT: integramos 3 de nuestros 6 servidores Proxmox en un cluster hiperconvergente. Este cambio no solo mejora la eficiencia, sino que también eleva la resiliencia de nuestros sistemas.
Un cluster agrupa múltiples servidores para trabajar como una única entidad. Optamos a agrupar los servidores en un cluster fundamentalmente porque permite
administrar todos los servidores desde una única interfaz, simplificando tareas como backups, actualizaciones o despliegues.
Una infraestructura hiperconvergente (HCI) integra en cada nodo los recursos de cómputo, almacenamiento y redes, eliminando la dependencia de sistemas externos como SAN o NAS. Esto reduce costes y complejidad, mientras ofrece redundancia, escalabilidad y rendimiento.
En nuestro proyecto, usamos Ceph (almacenamiento distribuido open-source) para lograr esta hiperconvergencia. La instalación de nuestra red de fibra dedicada a 10 Gbps permitió interconectar los nodos de forma eficiente, separando dos redes críticas:
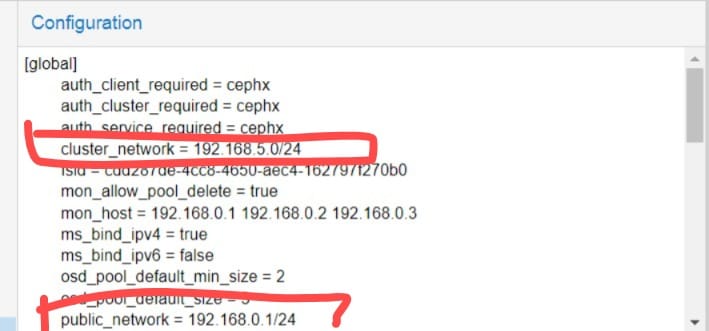
cluster_network(red de cluster):- Uso: Comunicación interna entre componentes de Ceph (OSDs, monitores).
- Función: Sincronización de datos, replicación y mantenimiento del cluster.
- Beneficio: Alto ancho de banda y baja latencia para operaciones críticas (ej.: recuperación tras fallos).
public_network(red pública):- Uso: Acceso externo al cluster (tráfico de clientes, VMs/containers, administración).
- Función: Comunicación con usuarios finales y servicios externos.
- Beneficio: Aislamiento del tráfico de gestión para evitar congestión.
La fibra garantiza velocidad y estabilidad en la cluster_network, vital para la sincronización masiva de datos entre OSDs. Por otro lado, aislar la red interna reduce riesgos de interferencias o ataques a la par que evita que el tráfico público sature la comunicación crítica entre nodos.
Aunque la implementación inicial del cluster Proxmox con Ceph fue técnicamente sólida en sistemas y redes, al llevarlo a producción con la carga masiva de máquinas virtuales del alumnado de ASIR, surgieron graves problemas de rendimiento que hicieron inviable su uso concurrente. Aquí el desglose de los fallos detectados y la solución adoptada:
- Problema inicial:
Las redescluster_network(comunicación interna de Ceph) ypublic_network(acceso externo) estaban invertidas:- La
cluster_networkusaba Ethernet de 1 Gbps, insuficiente para la sincronización masiva de datos entre OSDs. - La
public_networkutilizaba fibra de 10 Gbps, infrautilizada para tráfico menos crítico.
- La
- Corrección parcial:
Al invertir las redes, asignando la fibra (10 Gbps) a lacluster_network, se mejoró ligeramente el rendimiento. Sin embargo, no fue suficiente debido a otros cuellos de botella. - Discos NVMe en PCIe:
- Los OSDs (Object Storage Daemons) usaban discos NVMe conectados vía PCIe, pero su rendimiento se había degradado por el uso intensivo, ofreciendo solo 300 MB/s (muy por debajo de los +3,000 MB/s teóricos).
- Posible causa: Discos NVMe de gama baja o consumo, no diseñados para cargas de trabajo empresariales continuas.
- Controladora SAS:
- La controladora SAS operaba a 3 Gbps (velocidad SATA II), limitando los discos SSD de 2.5" a un máximo de ~300 MB/s.
- Esto generaba un cuello de botella crítico, ya que Ceph requiere alta velocidad de lectura/escritura para replicar datos entre nodos.
- Pruebas de velocidad:
La red de fibra, teóricamente de 10 Gbps, solo alcanzaba 4 Gbps en la práctica.- Causas posibles: Cuello de botella del bus PCI Express versión 1.0 de los servidores que no aprovecha el potencial de las nuevas tarjetas de red SFP+
La combinación de estos problemas generó:
- Latencia elevada: Las operaciones de lectura/escritura en Ceph se ralentizaron debido a discos lentos y red insuficiente.
- Inestabilidad en réplicas: La sincronización entre OSDs no cumplía los tiempos requeridos, provocando timeouts.
- Bloqueos en uso concurrente: Con cientos de máquinas virtuales activas, el sistema colapsaba por incapacidad de escalar.
Solución Final: Migración a ZFS en Configuración RAID 10
Ante la imposibilidad de resolver los cuellos de botella sin una inversión mayor en hardware y redes, se optó por:
- Desarticular Ceph: Eliminar la complejidad inherente a su arquitectura distribuida.
- Implementar ZFS-1 (similar a RAID 10):
- Ventajas:
- Rendimiento predecible: Almacenamiento local sin dependencia de redes internas.
- Redundancia: Espejado de discos (RAID 1) y striping (RAID 0) para equilibrio entre velocidad y tolerancia a fallos.
- Simplicidad: Menos sobrecarga de coordinación entre nodos.
- Ventajas:
En estos momentos, el cluster de virtualización Proxmox del IES Zaidín-Vergeles, recurso esencial para el desarrollo de las prácticas del alumnado de ASIR, opera con estabilidad aceptable gracias a una solución temporal implementada para garantizar la continuidad del servicio docente. Aunque se siguen utilizando los discos SSD y NVMe heredados de la infraestructura anterior —que en el peor de los casos ofrecen un rendimiento combinado cercano a los 600 MB/s—, priorizo mantener la disponibilidad del sistema mientras se evalúan alternativas definitivas. Esta decisión, impulsada por el profesorado para evitar interrupciones en la docencia, permite al alumnado acceder a las máquinas virtuales y realizar sus proyectos formativos, aunque con limitaciones de rendimiento que estamos trabajando en resolver a medio plazo (verano 2025).

Member discussion: